

One of the main advantages of GNU Prolog is its ability to produce stand alone executables. A Prolog program can be compiled to native code to give rise to a machine-dependent executable using the GNU Prolog compiler. However native-code predicates cannot be listed nor fully debugged. So there is an alternative to native-code compilation: byte-code compilation. By default the GNU Prolog compiler produces native-code but via a command-line option it can produce a file ready for byte-code loading. This is exactly what consult/1 does as was explained above (section 4.2.3). GNU Prolog also manages interpreted code using a Prolog interpreter written in Prolog. Obviously interpreted code is slower than byte-code but does not require the invocation of the GNU Prolog compiler. This interpreter is used each time a meta-call is needed as by call/1 (section 7.2.3). This also the case of dynamically asserted clauses. The following table summarizes these three kinds of codes:
| Type | Speed | Debug ? | For what |
| interpreted-code | slow | yes | meta-call and dynamically asserted clauses |
| byte-code | medium | yes | consulted predicates |
| native-code | fast | no | compiled predicates |
Native-code compilation: a Prolog source is compiled in several stages to produce an object file that is linked to the GNU Prolog libraries to produce an executable. The Prolog source is first compiled to obtain a WAM [9] file. For a detailed study of the WAM the interested reader can refer to “Warren’s Abstract Machine: A Tutorial Reconstruction” [1]. The WAM file is translated to a machine-independent language specifically designed for GNU Prolog. This language is close to a (universal) assembly language and is based on a very reduced instruction set. For this reason this language is called mini-assembly (MA). The mini-assembly file is then mapped to the assembly language of the target machine. This assembly file is assembled to give rise to an object file which is then linked with the GNU Prolog libraries to provide an executable. The compiler also takes into account Finite Domain constraint definition files. It translates them to C and invoke the C compiler to obtain object files. The following figure presents this compilation scheme:
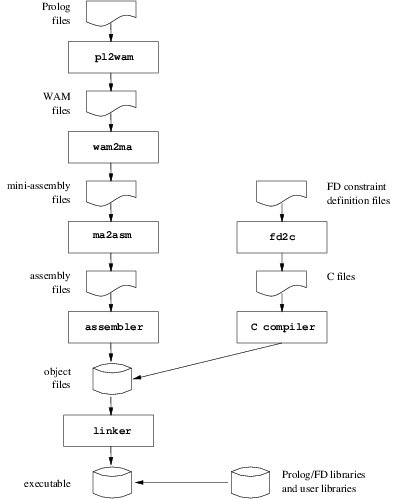
Obviously all intermediate stages are hidden to the user who simply invokes the compiler on his Prolog file(s) (plus other files: C,…) and obtains an executable. However, it is also possible to stop the compiler at any given stage. This can be useful, for instance, to see the WAM code produced (perhaps when learning the WAM). Finally it is possible to give any kind of file to the compiler which will insert it in the compilation chain at the stage corresponding to its type. The type of a file is determined using the suffix of its file name. The following table presents all recognized types/suffixes:
| Suffix of the file | Type of the file | Handled by: |
| .pl, .pro, .prolog | Prolog source file | pl2wam |
| .wam | WAM source file | wam2ma |
| .ma | Mini-assembly source file | ma2asm |
| .s | Assembly source file | the assembler |
| .c, .C, .CC, .cc, .cxx, .c++, .cpp | C or C++ source file | the C compiler |
| .fd | Finite Domain constraint source file | fd2c |
| any other suffix (.o, .a,…) | any other type (object, library,…) | the linker (C linker) |
Byte-code compilation: the same compiler can be used to compile a source Prolog file for byte-code. In that case the Prolog to WAM compiler is invoked using a specific option and produces a WAM for byte-code source file (suffixed .wbc) that can be later loaded using load/1 (section 8.23.2). Note that this is exactly what consult/1 (section 8.23.1) does as explained above (section 4.2.3).
The GNU Prolog compiler is a command-line compiler similar in spirit to a Unix C compiler like gcc. To invoke the compiler use the gplc command as follows:
| % gplc [OPTION]… FILE… | (the % symbol is the operating system shell prompt) |
The arguments of gplc are file names that are dispatched in the compilation scheme depending on the type determined from their suffix as was explained previously (section 4.4.2). All object files are then linked to produce an executable. Note however that GNU Prolog has no module facility (since there is not yet an ISO reference for Prolog modules) thus a predicate defined in a Prolog file is visible from any other predicate defined in any other file. GNU Prolog allows the user to split a big Prolog source into several files but does not offer any way to hide a predicate from others.
The simplest way to obtain an executable from a Prolog source file prog.pl is to use:
This will produce an native executable called prog which can be executed as follows:
However, there are several options that can be used to control the compilation:
General options:
Prolog to WAM compiler options:
WAM to mini-assembly translator options:
| --comment | include comments in the output file |
Mini-assembly to assembly translator options:
| --comment | include comments in the output file |
| --pic | produce position independent code (PIC) |
C compiler options:
| --c-compiler FILE | use FILE as C compiler/linker |
| -C OPTION | pass OPTION to the C compiler |
Assembler options:
| -A OPTION | pass OPTION to the assembler |
Linker options:
It is possible to only give the prefix of an option if there is no ambiguity.
The name of the output file is controlled via the -o FILE option. If present the output file produced will be named FILE. If not specified, the output file name depends on the last stage reached by the compiler. If the link is not done the output file name(s) is the input file name(s) with the suffix associated with the last stage. If the link is done, the name of the executable is the name (without suffix) of the first file name encountered in the command-line. Note that if the link is not done -o has no sense in the presence of multiple input file names. For this reason, several meta characters are available for substitution in FILE:
By default the compiler runs in the native-code compilation scheme. To generate a WAM file for byte-code use the --wam-for-byte-code option. The resulting file can then be loaded using load/1 (section 8.23.2).
To execute the Prolog to WAM compiler in a given read environment (operator definitions, character conversion table,…) use --pl-state FILE. The state file should be produced by write_pl_state_file/1 (section 8.22.5).
By default the Prolog to WAM compiler inlines calls to some deterministic built-in predicates (e.g. arg/3 and functor/3). Namely a call to such a predicate will not yield a classical predicate call but a simple C function call (which is obviously faster). It is possible to avoid this using --no-inline.
Another optimization performed by the Prolog to WAM compiler is unification reordering. The arguments of a predicate are reordered to optimize unification. This can be deactivated using --no-reorder. The compiler also optimizes the unification/loading of nested compound terms. More precisely, the compiler emits optimized instructions when the last subterm of a compound term is itself a compound term (e.g. lists). This can be deactivated using --no-opt-last-subterm.
By default the Prolog to WAM compiler fully optimizes the allocation of registers to decrease both the number of instruction produced and the number of used registers. A good allocation will generate many void instructions that are removed from the produced file except if --keep-void-inst is specified. To prevent any optimization use --no-reg-opt while --min-reg-opt forces the compiler to only perform simple register optimizations.
The Prolog to WAM compiler emits an error when a control construct or a built-in predicate is redefined. This can be avoided using --no-redef-error. The compiler also emits warnings for suspicious predicate definitions like -/2 since this often corresponds to an earlier syntax error (e.g. - instead of _. This can be deactivated by specifying --no-susp-warn. Finally, the compiler warns when a singleton variable has a name (i.e. not the generic anonymous name _). This can be deactivated specifying --no-singl-warn.
Internally, predicate names are encoded to fit the syntax of (assembly) identifiers. For this GNU Prolog uses it own name mangling scheme. This is explained in more detail later (section 4.4.6). By default the error messages from the linker (e.g. multiple definitions for a given predicate, reference to an undefined predicate,…) are filtered to replace an internal name representation by the real predicate name (demangling). Specifying the --no-demangling prevents gplc from filtering linker output messages (internal identifiers are then shown).
When producing an executable it is possible to specify default stack sizes (using --STACK_NAME-size) and to prevent it from consulting environment variables (using --fixed-sizes) as was explained above (section 4.3). By default the produced executable will include the top-level, the Prolog/WAM debugger and all Prolog and FD built-in predicates. It is possible to avoid linking the top-level (section 4.2) by specifying --no-top-level. In this case, at least one initialization/1 directive (section 7.1.14) should be defined. The option --no-debugger does not link the debugger. To include only used built-in predicates that are actually used the options --no-pl-bips and/or --no-fd-bips can be specified. For the smallest executable all these options should be specified. This can be abbreviated by using the shorthand option --min-bips. By default, executables are not stripped, i.e. their symbol table is not removed. This table is only useful for the C debugger (e.g. when interfacing Prolog and C). To remove the symbol table (and then to reduce the size of the final executable) use --strip. Finally --min-size is a shortcut for --min-bips and --strip, i.e. the produced executable is as small as possible.
Example: compile and link two Prolog sources prog1.pl and prog2.pl. The resulting executable will be named prog1 (since -o is not specified):
Example: compile the Prolog file prog.pl to study basic WAM code. The resulting file will be named prog.wam:
Example: compile the Prolog file prog.pl and its C interface file utils.c to provide an autonomous executable called mycommand. The executable is not stripped to allow the use of the C debugger:
Example: detail all steps to compile the Prolog file prog.pl (the resulting executable is stripped). All intermediate files are produced (prog.wam, prog.ma, prog.s, prog.o and the executable prog):
% gplc -W prog.pl % gplc -M --comment prog.wam % gplc -S --comment prog.ma % gplc -c prog.s % gplc -o prog -s prog.o
In this section we explain what happens when running an executable produced by the GNU Prolog native-code compiler. The default main function first starts the Prolog engine. This function collects all linked objects (issued from the compilation of Prolog files) and initializes them. The initialization of a Prolog object file consists in adding to appropriate tables new atoms, new predicates and executing its system directives. A system directive is generated by the Prolog to WAM compiler to reflect a (user) directive executed at compile-time such as op/3 (section 7.1.11). Indeed, when the compiler encounters such a directive it immediately executes it and also generates a system directive to execute it at the start of the executable. When all system directives have been executed the Prolog engine executes all initialization directives defined with initialization/1 (section 7.1.14). If several initialization directives appear in the same file they are executed in the order of appearance. If several initialization directives appear in different files the order in which they are executed is machine-dependant. However, on most machines the order will be the reverse order in which the associated files have been linked (this is not true under native win32). When all initialization directives have been executed the default main function looks for the GNU Prolog top-level. If present (i.e. it has been linked) it is called otherwise the program simply ends. Note that if the top-level is not linked and if there is no initialization directive the program is useless since it simply ends without doing any work. The default main function detects such a behavior and emits a warning message.
Example: compile an empty file prog.pl without linking the top-level and execute it:
% gplc --no-top-level prog.pl % prog Warning: no initial goal executed use a directive :- initialization(Goal) or remove the link option --no-top-level (or --min-bips or --min-size)
In this section we show how to define a new top-level extending the GNU Prolog interactive interpreter with new predicate definitions. The obtained top-level can then be considered as an enriched version of the basic GNU Prolog top-level (section 4.2). Indeed, each added predicate can be viewed as a predefined predicate just like any other built-in predicate. This can be achieved by compiling these predicates and including the top-level at link-time.
The real question is: why would we include some predicates in a new top-level instead of simply consulting them under the GNU Prolog top-level ? There are two reasons for this:
To define a new top-level simply compile the set of desired predicates and linking them with the GNU Prolog top-level (this is the default) using gplc (section 4.4.3).
Example: let us define a new top-level called my_top_level including all predicates defined in prog.pl:
By the way, note that if prog.pl is an empty Prolog file the previous command will simply create a new interactive interpreter similar to the GNU Prolog top-level.
Example: as before where some predicates of prog.pl call C functions defined in utils.c:
To obtain a fully extended executable, it is desirable to accept the same set of opions as the original top-level, see (section 4.2), e.g. --init-goal. For this it is necessary to link main() function used by the original top-level. This can be achieved passing the --new-top-level to gplc:
In conclusion, defining a particular top-level is nothing else but a particular case of the native-code compilation. It is simple to do and very useful in practice.
When the GNU Prolog compiler compiles a Prolog source to an object file it has to associate a symbol to each predicate name. However, the syntax of symbols is restricted to identifiers: string containing only letters, digits or underscore characters. On the other hand, predicate names (i.e. atoms) can contain any character with quotes if necessary (e.g. ’x+y=z’ is a valid predicate name). The compiler may thus have to encode predicate names respecting the syntax of identifiers. In addition, Prolog allows the user to define several predicates with the same name and different arities, for this GNU Prolog encodes predicate indicators (predicate name followed by the arity). Finally, to support modules in the future, the module name is also encoded.
Since version 1.4.0, GNU Prolog adopts the following name mangling scheme. A predicate indicator of the form [MODULE:]PRED/N (where the MODULE can be omitted) will give rise to an identifier of the following form: XK_[E(MODULE)__]E(PRED)__aN where:
Examples:
| Predicate indicator | internal identifier |
| father/2 | X0_father__a2 |
| ’x+y=z’/3 | X1_782B793D7A__a3 |
| util:same/2 | X2_util__same__a2 |
| util:same__1/3 | X3_util__73616D655F5F31__a3 |
So, from the mini-assembly stage, each predicate indicator is handled via its name mangling identifier. The knowledge of this scheme is normally not of interest for the user, i.e. the Prolog programmer. For this reason the GNU Prolog compiler hides this mangling. When an error occurs on a predicate (undefined predicate, predicate with multiple definitions,…) the compiler has to decode the symbol associated with the predicate indicator (name demangling). For this gplc filters each message emitted by the linker to locate and decode eventual predicate indicators. This filtering can be deactivated specifying --no-demangling when invoking gplc (section 4.4.3).
This filter is provided as an utility that can be invoked using the hexgplc command as follows:
| % hexgplc [OPTION]… FILE… | (the % symbol is the operating system shell prompt) |
Options:
It is possible to give a prefix of an option if there is no ambiguity.
Without arguments hexgplc runs in decoding mode reading its standard input and decoding (demangling) each symbol corresponding to a predicate indicator. To use hexgplc in the encoding (mangling) mode the --encode option must be specified. By default hexgplc only decodes predicate indicators, this can be relaxed using --relax to also take into account simple predicate names (the arity can be omitted). It is possible to format the output of an encoded/decoded string using --printf FORMAT in that case each string S is passed to the C printf(3) function as printf(FORMAT,S).
Auxiliary predicates are generated by the Prolog to WAM compiler when simplifying some control constructs like ’;’/2 present in the body of a clause. They are of the form ’$NAME/ARITY_$auxN’ where NAME/ARITY is the predicate indicator of the simplified (i.e. father) predicate and N is a sequential number (a predicate can give rise to several auxiliary predicates). It is possible to force hexgplc to decode an auxiliary predicate as its father predicate indicator using --aux-father or as its father predicate indicator followed by the sequential number using --aux-father2.
If no file is specified, hexgplc processes its standard input otherwise each file is treated sequentially. Specifying the --cmd-line option informs hexgplc that each argument is not a file name but a string that must be encoded (or decoded). This is useful to encode/decode a particular string. For this reason the option -E (encode) and -D (decode) are provided as shorthand. Then, to obtain the mangling representation of a predicate PRED use:
NB: if PRED is a complex atom it is necessary to quote it (the quotes must be passed to hexgplc). Here is an example under bash:
% hexgplc -E \'x+y=z\'/3 X1_782B793D7A__a3
Or even more safely (using bash quotes to prevent bash from interpreting special characters):
% hexgplc -E \''x+y=z'\'/3 X1_782B793D7A__a3